
A Guide to On-Page SEO After the Google Leak
For years, on-page SEO was a discipline built on educated guesswork. Practitioners tested, inferred, and theorised. Google said clicks did not affect rankings. Google said there was no domain authority metric. Google said Chrome data was not used to rank pages. The SEO community believed differently, but could not prove it.
In 2024, two events ended the guessing. Google's internal Content Warehouse API documentation was accidentally made public, exposing thousands of confirmed ranking attributes the company had never acknowledged. And the US Department of Justice, through its landmark antitrust case against Google, compelled the company's own Vice President of Search to testify under oath about how the algorithm actually works.
The black box is open. This is what on-page SEO looks like when you can see inside it.

What On-Page SEO Actually Means in 2026
On-page SEO is the practice of optimising everything on a webpage itself to improve its visibility in search engines. It covers the technical elements that tell crawlers what a page is about, the content elements that demonstrate relevance and quality to both algorithms and readers, and the structural elements that ensure the page satisfies the user who clicked on it.
What the leak and the trial confirmed is that on-page SEO has never been about ticking boxes for crawlers. Every on-page signal Google genuinely uses ultimately traces back to one question: does this page make users satisfied? The ranking systems that matter most, which we will cover throughout this guide, are built on the foundation of real human behaviour at scale.
Understanding this changes how you approach every element of on-page optimisation.
The Architecture Behind the Rankings: What Google Confirmed
Before diving into the individual elements of on-page SEO, it is worth understanding the framework Google actually uses, because it explains why certain optimisations matter and others are largely theatre.
The DOJ trial testimony from Pandu Nayak, Google's Vice President of Search, revealed that every page in Google's system is scored along two fundamental dimensions: Quality (Q*) and Popularity (P*).
Quality (Q*) is a largely static, site-wide score assessing the overall trustworthiness and authority of a domain. It is influenced by PageRank, the confirmed siteAuthority metric from the leaked documents, and content quality signals accumulated over time. Pages on sites with a Q* score below 0.4 are ineligible for featured snippets and People Also Ask boxes altogether, regardless of how well-optimised the individual page is.
Popularity (P*) is the dynamic signal. It captures real-world user engagement with your pages. It is powered primarily by NavBoost, the click-based re-ranking system that analyses a rolling 13-month window of aggregated user interaction data. Every time a user clicks on your result, stays on your page, and does not immediately return to the search results, that is a positive signal feeding NavBoost. Every time a user bounces immediately, that is a negative one.
The practical implication is profound. On-page SEO is not just about ranking for a keyword. It is about creating pages that, once clicked, deliver an experience satisfying enough that users stay. The algorithm is watching.
The Ranking Pipeline Google Confirmed: Mustang, T*, NavBoost, and Twiddlers
Understanding Q* and P* as the two top-level signals is the starting point. What the leak revealed in far greater detail is the specific sequence of systems Google runs every document through before a result ever reaches a user. This pipeline matters because on-page SEO is not about satisfying one system. It is about passing through a series of distinct evaluation gates in sequence, and failing at any stage undoes everything before it.
The pipeline works as follows.
The first gate is a system called Mustang. Named explicitly throughout the leaked documentation, Mustang is the primary engine responsible for the initial scoring and ranking of web pages. It is where the intrinsic, on-page qualities of a document are evaluated: the relevance of the title tag to the query, the originality and depth of the content, and the presence or absence of spam signals. A page must qualify at this stage before it is considered for anything that follows. Mustang is where traditional on-page SEO factors do their foundational work.
Feeding into Mustang is the topicality system, formally designated T* in Google's confirmed architecture. The T* system computes a document's fundamental query-dependent relevance. It answers the question of how relevant this specific document is to the exact terms the user searched. Pandu Nayak, Google's VP of Search, testified that this system is composed of three core signals described internally as "ABC": Anchors (the text of inbound hyperlinks pointing to the page), Body (the presence and prominence of query terms within the page content itself), and Clicks (user dwell time after clicking).
Nayak emphasised that the words on the page and where they appear, particularly in the title, headings, and body text, are "actually kind of crucial" for ranking. These three signals are combined in what was described as a "relatively hand-crafted way," which means engineers deliberately built the weighting rather than leaving it entirely to a machine learning model.
Once Mustang has produced an initial ranked set of results, a second and arguably more powerful system takes over: NavBoost. NavBoost is a re-ranking system trained on a rolling 13-month window of aggregated user click data. Its function is to test the theoretical relevance that Mustang computed against the demonstrated utility that real users experience.
A page that Mustang ranks highly because it contains the right terms and structure can be significantly promoted or demoted by NavBoost depending on whether users actually stay on it. The system does not count raw clicks. It analyses nuanced behavioural signals including good clicks, bad clicks, and what the documentation calls lastLongestClicks, which is the signal generated when a user clicks on a result and stays long enough that the query appears to have been resolved. This is the algorithmic measure of user satisfaction.
The final layer is a set of re-ranking functions the documentation calls Twiddlers. These are editorial overlays that give Google final-stage control over the results. Several specific Twiddlers are named in the documentation. The FreshnessTwiddler boosts newer content for time-sensitive queries. The QualityBoost Twiddler amplifies pages with strong authority and trust signals. The RealTimeBoost Twiddler adjusts rankings for breaking news and emerging trends. There are also demotion Twiddlers that suppress content for issues including low-quality product reviews, mismatched links, and signals of user dissatisfaction from the SERP.
The strategic implication of this pipeline is significant. A page can be perfectly optimised for Mustang and still be demoted by NavBoost if users bounce immediately. A page that passes both Mustang and NavBoost can still be suppressed by a Twiddler if it operates in a sensitive niche and falls short of quality thresholds. Modern on-page SEO is not about achieving a single score. It is about ensuring a page qualifies, is validated by real user behaviour, and avoids demotion at each distinct stage of this pipeline.

The Clickbait Warning: Why Raw Clicks Can Hurt You
The DOJ trial included a specific warning about click data that most coverage of NavBoost omits entirely, and leaving it out gives readers an incomplete picture that could lead to actively counterproductive optimisation.
A Google engineer testified under oath that there is a "very strong observation that people tend to click on lower-quality, less-authoritative content" disproportionately. Clickbait titles, sensational claims, and misleading previews earn high initial click-through rates precisely because they trigger curiosity or emotion rather than because they accurately represent the content. The engineer warned explicitly: "If we were guided too much by clicks, our results would be of a lower quality than we're targeting."
This is why NavBoost does not simply count clicks. It weights the quality of user behaviour after the click, specifically through signals like lastLongestClicks (long dwell time indicating satisfaction) versus badClicks (rapid returns to the SERP indicating disappointment). A title engineered purely for maximum click-through rate, without regard for whether the content delivers on its promise, will generate high initial clicks followed by high bad click rates as users bounce back immediately. The net NavBoost signal from that pattern is negative.
The practical consequence is that the goal of title tag optimisation is not to maximise clicks. It is to attract the right click, from a user whose intent genuinely matches what the page contains, and then satisfy that user so completely that they have no reason to return to the SERP. Accurate, compelling titles that set and deliver on honest expectations consistently outperform misleading ones over the 13-month window that NavBoost operates across.

Search Intent: The Step That Comes Before Everything Else
The single most common reason a well-optimised page fails to rank is a mismatch between the content and the intent of the searcher. You can have a perfect title tag, comprehensive content, and excellent internal linking and still not rank if you have written the wrong type of content for what the user actually wants.
Search intent is the reason behind the search. Google has spent billions of dollars learning to understand it, and the SERP for any given keyword is its current best interpretation of what searchers are looking for.
Before writing a single word, type your target keyword into Google and study the results. Ask three questions. What content type dominates the results: are they blog posts, product pages, tools, videos, or definitions? What content format are they in: step-by-step guides, listicles, comparisons, case studies? And what content angle appears across most of the top results: are they aimed at beginners, focused on a particular year, taking a "best of" approach, or emphasising speed and simplicity?
These three factors — type, format, and angle — form what Ahrefs describes as the three Cs of search intent, and matching all three is the structural template your content needs before you write a word.
Getting intent wrong means writing content that Google's own testing has determined does not satisfy users who type that query. No amount of keyword optimisation overcomes that.

Keyword Research: Finding the Right Term to Target
Every piece of content targets one primary keyword. That keyword must have verified search volume, because content targeting a phrase nobody searches for will not generate traffic regardless of its quality.
Use a keyword research tool such as Ahrefs, Semrush, or Google Keyword Planner to confirm search volume before committing to a topic. Look beyond the primary keyword and identify the secondary terms and questions your post should cover. The Ahrefs "also rank for" report on competitor URLs, the Google Autocomplete suggestions, the People Also Ask boxes, and the Related Searches at the bottom of the SERP are all free sources of the semantic vocabulary your content needs.
Long-tail keywords deserve particular attention. A three or four-word phrase with a specific modifier, such as "on-page SEO checklist for ecommerce" rather than just "on-page SEO," will be far more achievable for a newer site, will convert better because the intent is more specific, and will often be the entry point to ranking for broader head terms as domain authority grows.
Title Tags: The First and Last Line of Defence
The title tag is the blue headline in Google search results. It is the first thing a searcher sees and the last decision point before they choose whether to click. It is also a confirmed relevance signal that tells Google the primary topic of the page.
The rules here are specific and evidence-backed.
Keep title tags between 50 and 60 characters. Google truncates longer titles, and the key information is lost. The closer your primary keyword is to the beginning of the title, the stronger the relevance signal and the more immediately recognisable it is to the searcher. Brian Dean's research across millions of pages consistently shows that front-loading the keyword correlates with stronger rankings, all other things being equal.
Include a modifier that adds specificity and captures long-tail traffic. Words like "guide," "checklist," "best," "how to," and year references all help a page rank for variations beyond the exact primary keyword without any additional optimisation. The modifier also makes the title more click-worthy by signalling comprehensiveness, recency, or specificity.
Write for humans, not for crawlers. A title tag that reads naturally and sets accurate expectations for what the reader will find will outperform a keyword-dense but robotic one. NavBoost measures whether the click was a good one. If your title tag misleads users into clicking on content that does not match their expectation, the resulting bad clicks will suppress rankings over time.
Every page on a site must have a unique title tag. Duplicate titles are a crawling and indexing inefficiency and they dilute the relevance signal of both pages.
What the Leak Confirmed About Content Quality: contentEffort and What Google Is Actually Measuring
The leak revealed an attribute called contentEffort defined in the documentation as an "LLM-based effort estimation for article pages." It sits within the QualityNsrPQData module, which is at the heart of Google's page quality evaluation systems. This is not a minor signal. It appears to be the technical engine behind what Google publicly calls the Helpful Content System.
The contentEffort score is calculated based on an assessment of how easily a piece of content could be replicated. Content that is generic, formulaic, or lacks original insight can be reproduced by any writer or AI model with minimal effort, and it scores poorly.
Content that contains original research, expert interviews, first-hand observations, custom analysis, and nuanced detail is difficult and expensive to replicate, and it scores well. A low contentEffort score likely functions as the primary classifier for unhelpful content, potentially triggering the site-wide demotion the Helpful Content System is designed to apply.
This is the technical specification behind the vague advice to "write for humans." Google is algorithmically measuring the effort invested in creating a piece of content and using it as a proxy for whether the content is worth ranking. The practical implication is that surface-level articles covering a topic at a cursory level are penalised not because they contain bad information but because they contain nothing that could not have been written by someone with a superficial understanding of the subject.
The leak also confirmed a related attribute called OriginalContentScore, which applies specifically to shorter content and scores it on a scale of zero to 512 based on uniqueness. For brief pieces, originality is the primary quality measure. The system uses technical methods including ContentChecksum96 (a fingerprint of the page's content) and shingleInfo (overlapping chunks of text used to detect duplication) to identify whether content is genuinely original or a thin reworking of something already on the web.
One additional detail from the documentation has significant implications for how content should be structured. The Mustang system has a maximum number of tokens it will process for any given document. Extremely long pages may be truncated, with content towards the end potentially ignored or given reduced weight. This is a data-backed argument for front-loading the most important information, evidence, and keyword-rich sections early in a post rather than burying them in a long article. The inverted pyramid structure is confirmed, not just recommended.
Meta Descriptions: The Sales Pitch for the Click
Meta descriptions are not a direct ranking signal. This was confirmed publicly by Google and is consistent with the trial evidence. However, they are a direct driver of click-through rate, and click-through rate feeds NavBoost, which is one of the most important ranking signals in the system.
Write a unique meta description for every page. When you leave the description blank, Google generates one automatically from the page content, and it is almost always worse than a carefully written one.
Keep descriptions under 160 characters for desktop and closer to 120 for mobile, where truncation happens sooner. Include the primary keyword because Google bolds matching terms in the snippet, drawing the eye and signalling relevance to the searcher.
The meta description has one job: to convince the right person to click. It is not the place for keyword density. It is the place to state the unique value of the page, confirm it answers the searcher's question, and give the reader a reason to choose your result over the other nine on the page.

Heading Structure: How Google Reads Your Page
Heading tags (H1 through H6) serve two equally important functions. They help Google understand the structure and scope of a page, and they help readers scan the content to find the sections most relevant to them. Both functions connect directly to ranking outcomes.
Your page should have exactly one H1 tag. The H1 is the on-page title and it should contain your primary keyword. This is one of the most foundational on-page signals across every credible source of SEO evidence. The DOJ trial confirmed that Google's topicality scoring (T*) uses what engineers called the "ABC" signals: Anchors, Body text, and Clicks. Your H1 is the most prominent body text signal on the page.
H2 tags are the chapter headings of your content. They should cover the major subtopics identified in your SERP and competitor analysis. Use secondary keywords and natural variations in H2s rather than repeating the exact primary keyword in every heading. A reader scanning only the H2 headings should understand the full scope of what the page covers.
H3 tags organise sub-points within H2 sections. Use them when a section has multiple distinct components that benefit from their own heading. Maintain strict hierarchy throughout: H1 leads to H2, H2 leads to H3. Never skip levels or use heading tags for visual styling purposes.
Writing your H2s as questions is one of the most consistently useful tactics for capturing People Also Ask positions. When your H2 matches the phrasing of a common PAA question and the answer immediately beneath it is direct and clearly worded, Google frequently pulls that answer into the SERP feature, generating additional visibility without any separate optimisation.
Two Confirmed Signals Most SEOs Have Never Heard Of
The Content Warehouse leak contained two attributes that are easy to overlook but have direct implications for how content should be structured and formatted.
The first is pageregions. This attribute encodes the positional ranges for different structural regions of a web page: the header, footer, sidebar, and main content area. The documentation strongly implies that Google's systems weight the content in each region differently. Words and links in the main body content are valued more highly than those in boilerplate footer text or navigational sidebar elements. This matters for internal linking (links placed naturally within the body of an article carry more weight than footer links), for keyword placement (terms in the main content region are scored differently from terms in navigation), and for passage indexing (clear heading-delineated sections in the main body create the distinct content chunks that AI Overviews and featured snippets extract from).
The second is a font size weighting signal. The documentation indicates that Google tracks the average weighted font size of terms within a document. This means words that are visually prominent, because they appear in heading tags with larger font sizes or are bolded within body text, are given more weight in the content analysis process. This is the algorithmic confirmation that using H1, H2, and H3 tags for primary and secondary keywords is not just a structural convention but a direct relevance signal. The heading hierarchy is the mechanism by which you communicate to both readers and the algorithm which terms are most important on the page.
Keyword Placement in the Body: Where the Confirmed Evidence Points
The primary keyword should appear in the first 100 to 150 words of the article. This is one of Brian Dean's most consistently tested on-page principles, and the logic behind it is straightforward. Google uses early-in-document keyword presence as a relevance confirmation. It also reduces the bounce rate that feeds bad NavBoost signals, because users who see their query reflected immediately know they are in the right place.
The introduction is not the place to be clever or abstract. It should tell the reader exactly what they are going to get, confirm the topic, and give them a reason to read on. Bad introductions are the most common cause of high bounce rates on otherwise strong content.
Throughout the rest of the body, use the primary keyword naturally where it fits. A practical guide is to aim for it to appear roughly every 300 to 500 words, but only where it reads naturally. Forced repetition of the same phrase is keyword stuffing, and keyword stuffing produces a poor reading experience, which produces bad NavBoost signals, which suppresses rankings. Use synonyms, variations, and related phrases instead.
The Three-Date Freshness System: Why Updating the Date Is Not Enough
One of the most actionable and least understood revelations from the Content Warehouse leak is the discovery that Google does not use a single date signal to assess content freshness. It uses three separate date attributes, each measuring freshness in a different way, and a content strategy that addresses only one of them is structurally incomplete.
The first date is BylineDate. This is the most familiar signal: the publication or last-updated date displayed on the page. It is what most publishers change when they "refresh" a piece of content. Google reads it and uses it, but it is the weakest of the three precisely because it is so easy to manipulate.
The second date is SyntacticDate. This is a date that Google's systems extract directly from the URL string or the page title. If a URL contains /2024/ or a title contains "Best Laptops 2024," that creates a permanent SyntacticDate signal embedded in the URL itself. Here is why this matters: a URL cannot be changed without breaking its historical record and losing the authority that has accumulated on that address. An article updated for 2026 with a new BylineDate will still carry a "2024" SyntacticDate from its URL, and these two signals will be in conflict. This is the data-backed reason for using evergreen URL structures that omit years entirely. The BylineDate can be updated. The SyntacticDate in the URL is immutable.
The third and most sophisticated date is SemanticDate. This is derived not from any metadata but from the content itself. Google's systems evaluate whether the facts, sources, statistics, and data referenced within the text are current relative to the broader corpus of information on the web about that topic. If an article about solar panel costs references SEAI grant figures from 2022, the SemanticDate will reflect that regardless of what the BylineDate says.
The documented attribute lastSignificantUpdate tracks the timestamp of the last substantive change to a document, allowing Google to distinguish between minor cosmetic edits and meaningful content revisions. The richcontentData attribute goes further still, storing information about what specific content was inserted, deleted, or replaced during an update, allowing the algorithm to assess the magnitude of a change.
The unified implication is that a genuine content freshness strategy cannot consist of updating the publication date and changing a few words. It must update the core substance: the statistics, the sources, the examples, and the recommendations. Changing only the BylineDate while leaving stale SemanticDate signals intact is not only ineffective but is specifically the behaviour Google's multi-date system was designed to detect and penalise.
The URL as Evidence: HostAge, DocumentHistory, and the Temporal Trust Model
The leaked documentation settles a debate that has run for years in the SEO community. Google representatives repeatedly and publicly denied the existence of a sandbox that suppresses new websites. The PerDocData module in the Content Warehouse documentation contains an attribute named hostAge with the explicit description that it is used "to sandbox fresh spam in serving time." The sandbox exists. It is confirmed in the code.
The mechanism is not a blanket punishment for being new. It is a risk-management system. Google's default position towards any new domain is one of inherent distrust because the line between a legitimate new site and sophisticated fresh spam is difficult for an algorithm to detect with confidence. The practical effect on the SERPs can look identical. The only way through this probationary period is by accumulating positive signals quickly: genuine editorial links, strong user engagement data showing that visitors are satisfied, and consistent topically focused publishing that demonstrates the site is a real entity with real intent.
The documentHistory signal extends this logic to individual pages. The documentation references a demotion for pages described as "without history, or a URL that is new to Search." This creates a two-tier temporal trust system. A brand-new website is subject to the hostAge sandbox at the domain level and the documentHistory demotion at the page level simultaneously. A new page published on an established domain bypasses the hostAge filter but still faces the documentHistory demotion until it accumulates enough positive signals to graduate from it.
This has a direct implication for URL strategy. The leak confirms that Google maintains a historical record of every URL it has ever indexed, using what appears to be the last twenty versions of a page when analysing its link and content history. Changing a URL, even with a 301 redirect, is a significant and costly action that effectively resets much of the trust associated with that address. Careful URL planning at the outset, combined with evergreen URL structures designed to remain relevant over years rather than months, is not just a technical best practice. It is a structural investment in the temporal trust that the algorithm rewards over time.

LSI Keywords, NLP, and Semantic Coverage: What the Leak Confirmed
This is where the distinction between old SEO mythology and confirmed reality matters most.
The term "LSI keywords" (Latent Semantic Indexing) refers to a mathematical model patented in 1989 that Google does not actually use. Despite the term appearing constantly in SEO content, it is technically inaccurate. Google uses BERT, RankEmbedBERT, MUM, and entity-based understanding. These are sophisticated language models that understand the contextual relationships between concepts, not a co-occurrence matrix from 1989.
However, the underlying practice that SEOs describe as "using LSI keywords" is genuinely important. The T* topicality scoring system in Google's confirmed architecture uses the Body text of a page as a primary relevance signal. That body text is evaluated not just for the presence of the primary keyword but for the presence of the vocabulary, entities, and related concepts that an expert covering this topic would naturally use.
The Content Warehouse leak confirmed the contentEffort attribute, described as an "LLM-based effort estimation for article pages." Google is algorithmically measuring the depth and originality of content. Shallow coverage of a topic, even at a reasonable word count, scores poorly. Comprehensive coverage that addresses the topic the way a genuine expert would, using the vocabulary of the field, the relevant entities, the expected subtopics, and the natural language of the domain, scores well.
The practical approach is to write like an expert, not like a keyword list. An expert writing about kitchen worktops naturally includes: quartz, granite, laminate, solid surface, heat resistance, maintenance, edge profiles, waterproofing, fitting costs, and specific brand names. They do not need a tool to include these terms because they know the subject. The tool, in this case NeuronWriter or Surfer SEO, is useful for identifying any terms an expert might inadvertently omit, not for generating a list of phrases to force into the content.
Use Google's People Also Ask boxes, Related Searches, competitor subheadings, and NLP tools to identify any semantic gaps in your draft. Fill the gaps where the terms fit naturally. Do not fill them where they do not.
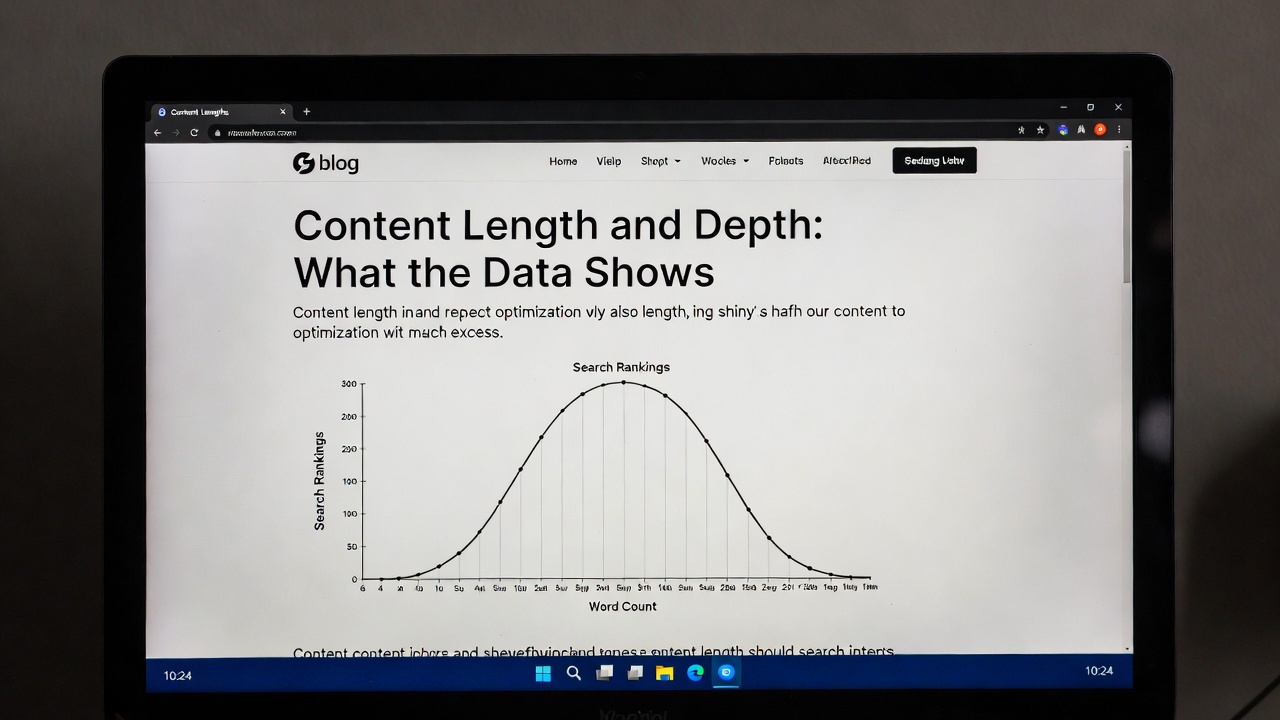
Content Length and Depth: What the Data Shows
There is no universal correct word count for a blog post. The right length is whatever is required to comprehensively satisfy the searcher's intent for the target keyword, no more and no less.
That said, the data is consistent. Pages ranking in positions one to three average 2,100 to 2,500 words. Pages ranking in positions eight to ten average 1,200 to 1,500 words. The average across the top ten results is approximately 1,890 words. Top-ranking content has grown 25% longer since 2020.
Longer content ranks better for several interconnected reasons. It naturally covers more semantic terms and expected subtopics. It earns more backlinks as a comprehensive resource. It generates longer dwell times when users find it genuinely useful. And the confirmed contentEffort attribute rewards demonstrably deep treatment of a topic.
However, padding content with repetition to hit an arbitrary word count is actively counterproductive. A user who reaches a padded section of a long article and clicks back to the SERP is generating a bad NavBoost signal that suppresses rankings. Content should be as long as it needs to be to cover the topic properly, and not a word longer.
Formatting for the Page That Keeps People Reading
The best-written content on the internet fails if it is presented as an unbroken wall of text. Formatting is not cosmetic. It is a direct driver of dwell time and a reduction in bounce rate, both of which feed the NavBoost signals that determine whether rankings rise or fall.
Keep paragraphs to two to four sentences on the web. On a screen, particularly a mobile screen, long paragraphs are visually intimidating and cause users to abandon the page before reading the content. Short paragraphs signal that reading is manageable and encourage continuation.
Use subheadings every 200 to 300 words to break content into scannable sections. Bold key terms and important takeaways so that a reader scanning rather than reading still absorbs the main points. Add a visual break in the form of an image, table, numbered list, or diagram every 300 to 500 words to provide relief and reinforce the information.
Include a table of contents with anchor links for any post over 1,500 words. This significantly improves the experience for users looking for a specific section and can generate sitelink-style jump links in the SERP, increasing the visual prominence of the result.
Write at a reading level your audience can process quickly. The Flesch-Kincaid Grade 7 to 9 range is appropriate for most general audience content. Shorter sentences and plain language are not a concession to simplicity. They are a commitment to clarity.
Internal Linking: The Most Under-Used On-Page Signal
Internal linking is consistently cited as one of the most impactful and most neglected on-page optimisations. The DOJ trial confirmed why it matters so much.
PageRank flows through internal links. The more internal links pointing to a page from other pages on the site, the more authority that page accumulates. The anchor text of those internal links is the "A" component of Google's confirmed T* topicality scoring: Anchors, Body text, Clicks. Descriptive internal link anchor text is a direct relevance signal for the linked page.
Every new blog post should include three to eight internal links pointing to related content, pillar pages, and commercially important pages. Every time a new post is published, existing relevant posts should be updated with a link to the new content. This retrospective internal linking is the mechanism by which a body of content becomes a coherent topical cluster rather than a collection of isolated pages.
Anchor text must be descriptive. Linking the phrase "click here" or "read more" is a wasted opportunity. Link the phrase that describes what the reader will find, such as "our guide to ecommerce category page optimisation" or "how to structure a blog post for featured snippets." This tells Google what the linked page is about from the context of the linking page.
Images: The Ranking Signals That Everyone Ignores
Images are not decorative. They carry SEO signals that are consistently under-utilised, particularly in blog content.
Every image must have alt text. Alt text serves two functions: it describes the image to screen readers for accessibility, and it describes it to crawlers that cannot see it. Include your primary keyword naturally in at least one image's alt text. All other alt text should describe what the image actually shows, accurately and specifically.
Name image files descriptively before uploading. The filename is crawled by Google as a relevance signal. on-page-seo-title-tag-example.jpg signals relevance. Screenshot_2026_03_14.jpg signals nothing.
Compress all images before upload. Uncompressed images are one of the most common causes of slow LCP scores, and slow page load directly damages Core Web Vitals performance. Use WebP format where possible. Specify width and height attributes on all image tags to prevent Cumulative Layout Shift during page load.
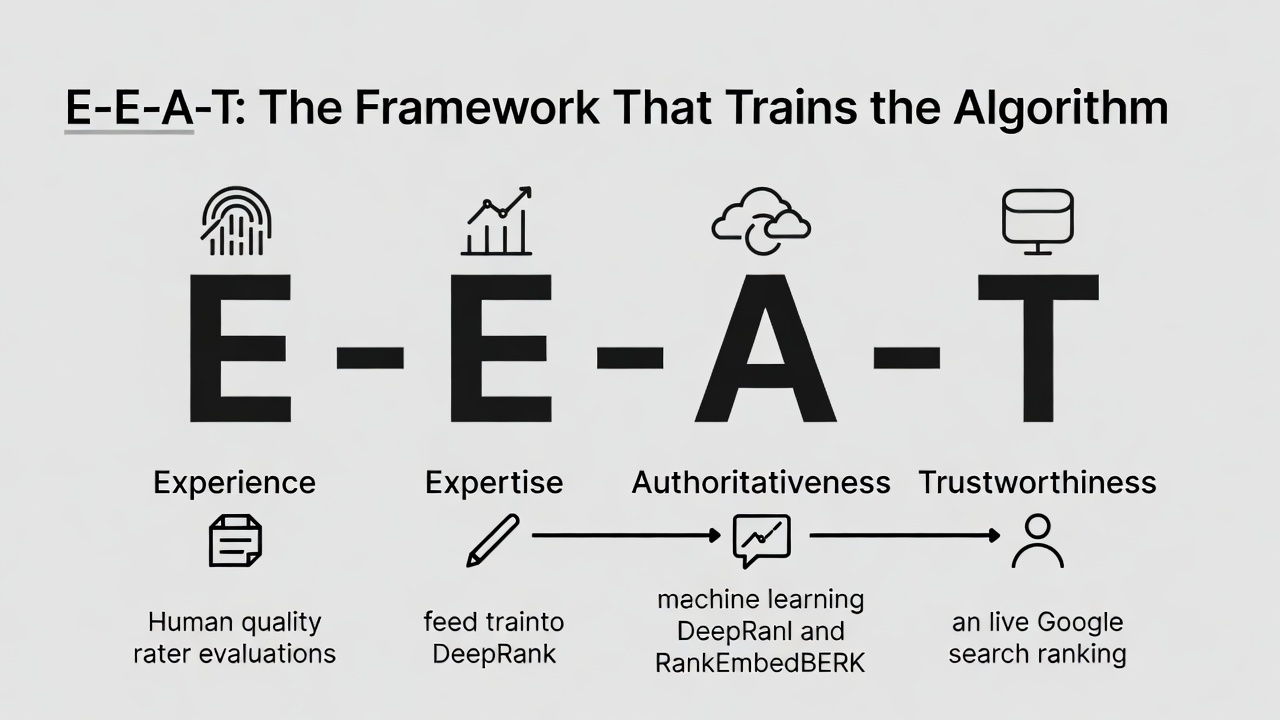
E-E-A-T: The Framework That Trains the Algorithm
E-E-A-T stands for Experience, Expertise, Authoritativeness, and Trustworthiness. It is the framework Google's human quality raters use to evaluate content, and those evaluations produce the training data for the ML models (DeepRank, RankEmbedBERT) deployed in live ranking. The DOJ trial confirmed this directly. The Quality Rater Guidelines are not aspirational communications about Google's values. They are the specification document for what the ranking algorithm is trying to measure.
Experience means demonstrating first-hand familiarity with the subject. Content written by someone who has actually done the thing is algorithmically distinguishable from content produced by research alone. Specific examples, original observations, case study evidence, and the particular details that only come from direct involvement all signal experience.
Expertise means demonstrating depth of knowledge. Cover the nuances, the edge cases, the common mistakes, and the details that surface-level coverage misses. The contentEffort attribute confirmed in the Content Warehouse leak algorithmically measures the depth and originality of the work.
Authoritativeness is built across the site over time through links, brand mentions, and consistent high-quality publishing within a defined topical area. The siteFocusScore confirmed in the leaked documents means Google measures how topically concentrated your entire site is, and rewards specialist sites with higher scores than generalist ones.
Trustworthiness means accurate information, named authors with visible credentials, a publication date, clear sourcing for facts and data, and the basic infrastructure of a credible site: contact details, privacy policy, and editorial standards. Every blog post should have a named author with a short bio that demonstrates their relevant expertise.
Schema Markup: Telling Google Explicitly What Your Content Is
Schema markup is structured data code added to a page that gives Google explicit information about the content type, author, publication date, and structure. It does not directly improve rankings but significantly increases the chances of rich results in the SERP, which improve click-through rates.
Article schema should be implemented on every blog post. It identifies the content as an article, includes the author, publisher, and date, and helps Google surface the correct metadata in search results.
FAQ schema is particularly valuable for posts with a dedicated FAQ section. When implemented correctly, it can display individual questions and answers directly beneath the main result in the SERP, effectively doubling or tripling the vertical space your result occupies on the page.
HowTo schema works similarly for step-by-step instructional content, displaying individual steps in the search results. For tutorial and guide content, this can be a significant CTR driver.
Validate all schema implementations using Google's Rich Results Test before publication. Broken schema generates warnings in Search Console and does not produce the rich results it is intended to unlock.
The Pre-Publish Checklist: Every Element Before the Post Goes Live
Running through this list before publishing ensures nothing important has been missed.
On strategy: the primary keyword has confirmed search volume; the content type, format, and angle match the intent confirmed by the SERP; the post fits within or initiates a content cluster aligned with the site's topical focus.
On title and meta: the title tag contains the primary keyword near the front; the title is under 60 characters; a power modifier is included; the meta description is hand-written, under 160 characters, contains the keyword, and pitches the click effectively.
On structure: one H1 containing the primary keyword; H2s covering all expected subtopics identified in competitor analysis; question-format H2s used where relevant; heading hierarchy correct throughout; table of contents present for posts over 1,500 words.
On content: primary keyword in the first 100 to 150 words; primary keyword used naturally throughout with synonyms and variations; NLP terms from NeuronWriter or Surfer integrated where they fit; PAA questions answered explicitly; content length appropriate to the competitive landscape.
On formatting: paragraphs are two to four sentences; visual break every 300 to 500 words; key terms bolded; introduction hooks the reader and includes a clear promise.
On linking: three to eight internal links with descriptive anchor text; link to the pillar page if this is a cluster post; existing posts updated with a link to this new content; external links to authoritative sources where relevant.
On images: every image has descriptive alt text; primary keyword included in at least one alt text naturally; file names are descriptive; images are compressed; dimensions are specified.
On trust: named author with relevant bio; publication date visible; facts and statistics cited with sources; structured data validated.
Frequently Asked Questions About On-Page SEO
Does on-page SEO still matter when Google uses AI to understand content?
It matters more than ever. The DOJ trial confirmed that Google's ranking architecture uses hand-crafted signals as the backbone of the system, with ML models applied as additional layers on top. Google's own engineers testified that "the vast majority of signals are hand-crafted" because they need to be transparent and debuggable. Fundamental on-page signals including keyword placement, heading structure, and content quality remain the foundation of how relevance is assessed.
How long should a blog post be for SEO?
Long enough to comprehensively cover the topic and satisfy the intent of the searcher, and not a word longer. For most informational blog posts, this is between 1,500 and 2,500 words. For comprehensive pillar page guides, it is often 3,000 words or more. The key is that length should be a byproduct of genuine depth, not padding to hit an arbitrary target.
Do clicks really affect rankings?
Yes. The DOJ trial provided the clearest confirmation the SEO community has ever had. Pandu Nayak, Google's VP of Search, testified under oath that NavBoost, a system using a rolling 13-month window of user click data, is "one of the important signals" in Google's ranking system. Google's own internal documents state that "learning from this user feedback is perhaps the central way that web ranking has improved for 15 years." Every on-page decision that improves user experience is, directly or indirectly, an on-page ranking decision.
What is the difference between on-page SEO and technical SEO?
On-page SEO covers the content and structural elements on individual pages: title tags, meta descriptions, headings, keywords, content quality, internal linking, images, and schema. Technical SEO covers the infrastructure of the site: crawlability, indexation, site speed, Core Web Vitals, HTTPS, redirect handling, and XML sitemaps. Both are necessary. Technical SEO ensures Google can access and process your pages. On-page SEO ensures those pages are worth ranking when Google finds them.
How quickly do on-page SEO improvements affect rankings?
Changes to title tags and meta descriptions can influence click-through rates within days of Google recrawling the page. Content changes that improve relevance and depth typically take four to eight weeks to show in rankings as Google recrawls, reindexes, and reassesses the page within its current context. NavBoost signals accumulate over the 13-month rolling window, so sustained improvements in user engagement produce lasting ranking gains rather than temporary spikes.
The Bottom Line on On-Page SEO in 2026
The Google leak and the DOJ trial did not change what good on-page SEO looks like. They confirmed it. The practitioners who spent years arguing that user engagement matters, that domain authority is real, that content depth beats keyword density, and that satisfying the reader is the goal were right all along.
What has changed is that we no longer have to argue from inference. We have the confirmed architecture. We know the signals that matter, the systems that measure them, and the hierarchy of importance. On-page SEO built on that foundation is not guesswork. It is engineering.
Every page you publish should be the most genuinely useful version of itself for the reader who searched for it. That principle has always been the right one. Now we know it is also precisely what the algorithm measures. If you want a team who works to that standard on your behalf, take a look at our SEO services and get in touch.





